We keep bringing you new things, following up on the 10/10 spirit. Today’s news: read replicas are now available in the Free Plan. This is particularly great if you’ve been curious to test out how awesome they are.
Why are we doing this? Read Replicas are just another way to use your compute hours. Our Free Plan includes 190 CU-hours, enough to run the smallest compute 24/7 if that’s what you prefer. But if you don’t need your database running all the time, you can invest your compute hours in more projects (you now get ten), higher capacity (via autoscaling) or, now, in read replicas.
Neon read replicas crash course
Read replicas may not sound like the most exciting feature: they’ve been around for a while as a table-stakes feature of managed databases, acting as tools for offloading reporting and analytics tasks from the primary database. Traditional read replicas work by asynchronously copying data from the primary database to a secondary instance using log-based replication mechanisms: changes are recorded in a Write-Ahead Log (WAL) and replayed on the replica to keep it in sync with the primary. We discussed the state of the art of replicas in a previous blog post.
But Neon takes a fundamentally different approach to read replicas, taking advantage of its unique serverless architecture. Neon separates storage and compute while implementing a custom-built storage layer that allows multiple compute endpoints to be attached to the same storage unit. As a result, Neon’s read replicas don’t need to copy or duplicate data—both the primary compute and the read replicas access the same data source directly from Neon’s storage layer, which persists data across all replicas.
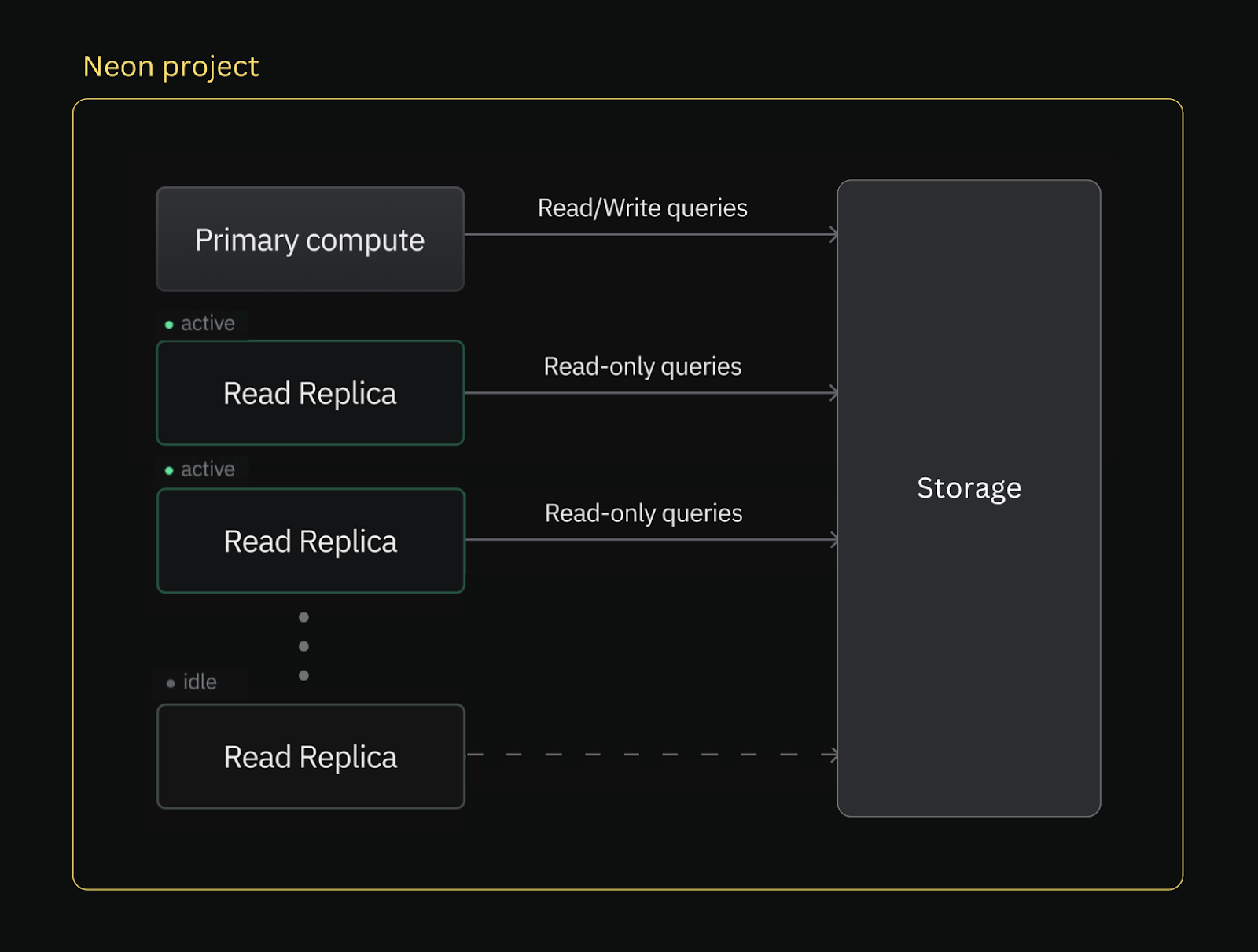
This architectural difference brings three key advantages:
- Lighter and cost-efficient. In traditional setups, read replicas need additional storage to maintain a copy of the primary database, so they quickly get heavy and expensive. In Neon, all replicas read from a shared storage backend. You can create hundreds of them, and you only pay for storage once.
- Worry-free management. Neon’s read replicas scale to zero when idle. This not only saves you even more costs but also eases maintenance pressure. You don’t have to worry about your read replicas once they’re created. They’re virtually free if nobody’s using them.
- Fast to deploy. Since no data needs to actually be replicated, read replicas in Neon are created and deleted almost instantly. If someone needs to query the database, they can immediately get their isolated connection string.
Two use cases
Safe, low-cost read access for teams
The most popular use case for read replicas in Neon is granting read access to your data without compromising your primary database. For example, there might be team members who need to run queries for reporting or analysis; thanks to the lightweight nature of Neon’s read replicas, you can create dedicated replicas for each person, each with their own access URL. All while ensuring that:
- Your main compute stays safe. You don’t have to worry about someone running an inefficient or heavy SQL query that could jeopardize the performance of your database or, worse, break something critical.
- Costs stay low by default. You can create many replicas without worrying about the cost. If nobody is actively querying a replica, it automatically suspends itself.
Horizontal scaling
Another popular use case for Neon read replicas is helping teams scale compute horizontally. If you’re running a write-heavy workload in production, you could use read replicas to offload read queries, relieving pressure on the primary compute and ensuring that your application continues running with optimal performance.
But you can even do this if your primary workload isn’t that heavy. Instead of scaling your primary database by increasing the compute autoscaling limit, you could create multiple read replicas and distribute your queries across them, keeping all your computes small.
Create your first read replica
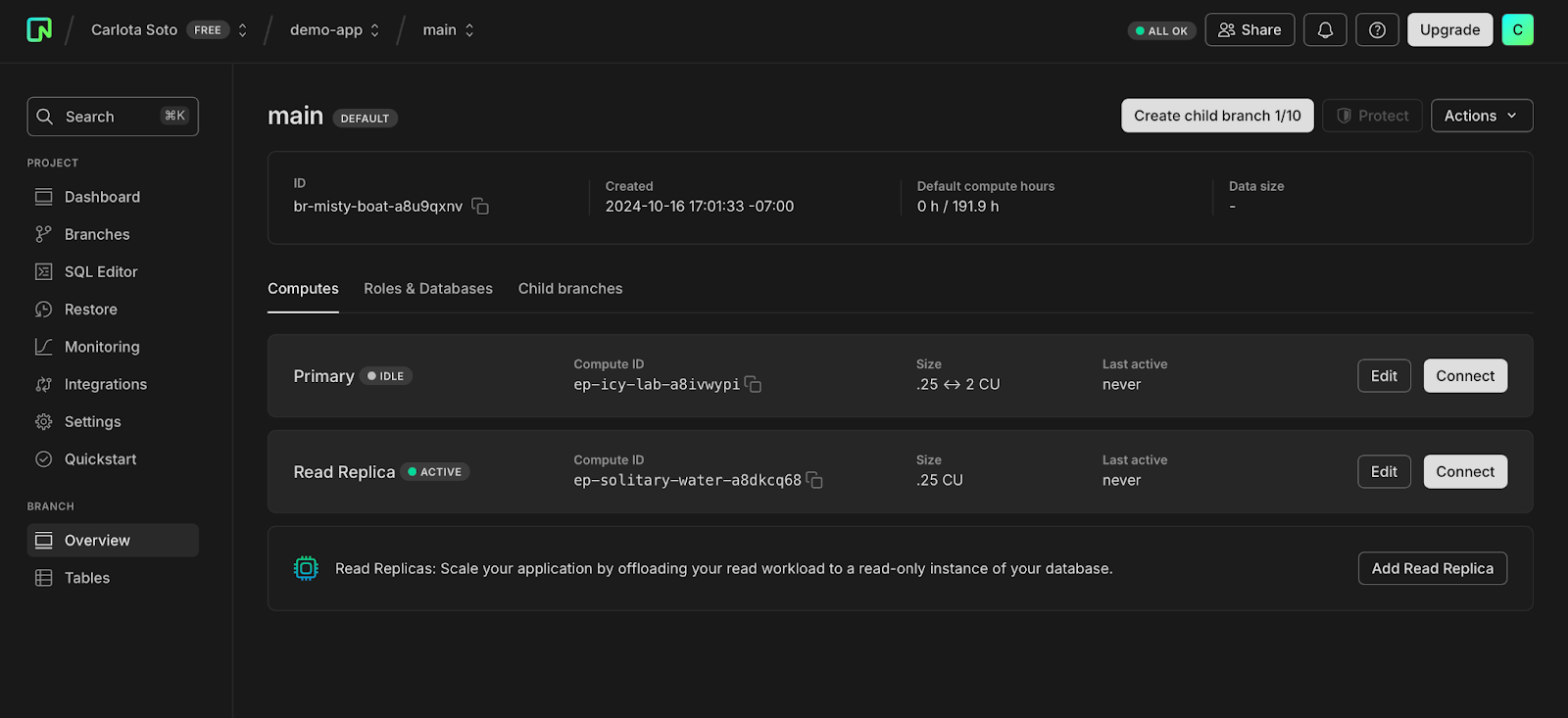
In your Neon Free account, navigate to the branch you’d like to add a read replica to and select Add Read Replica:
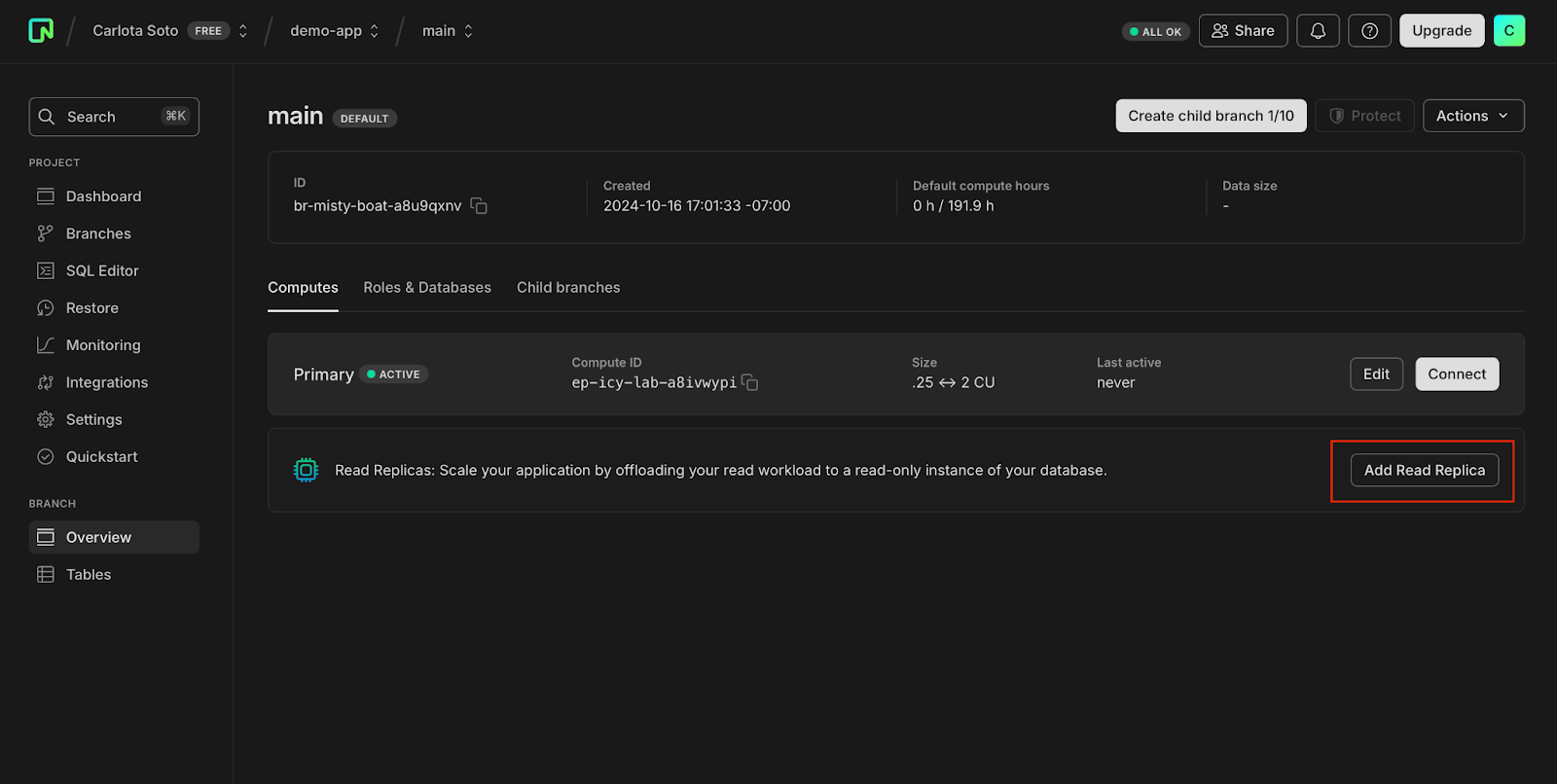
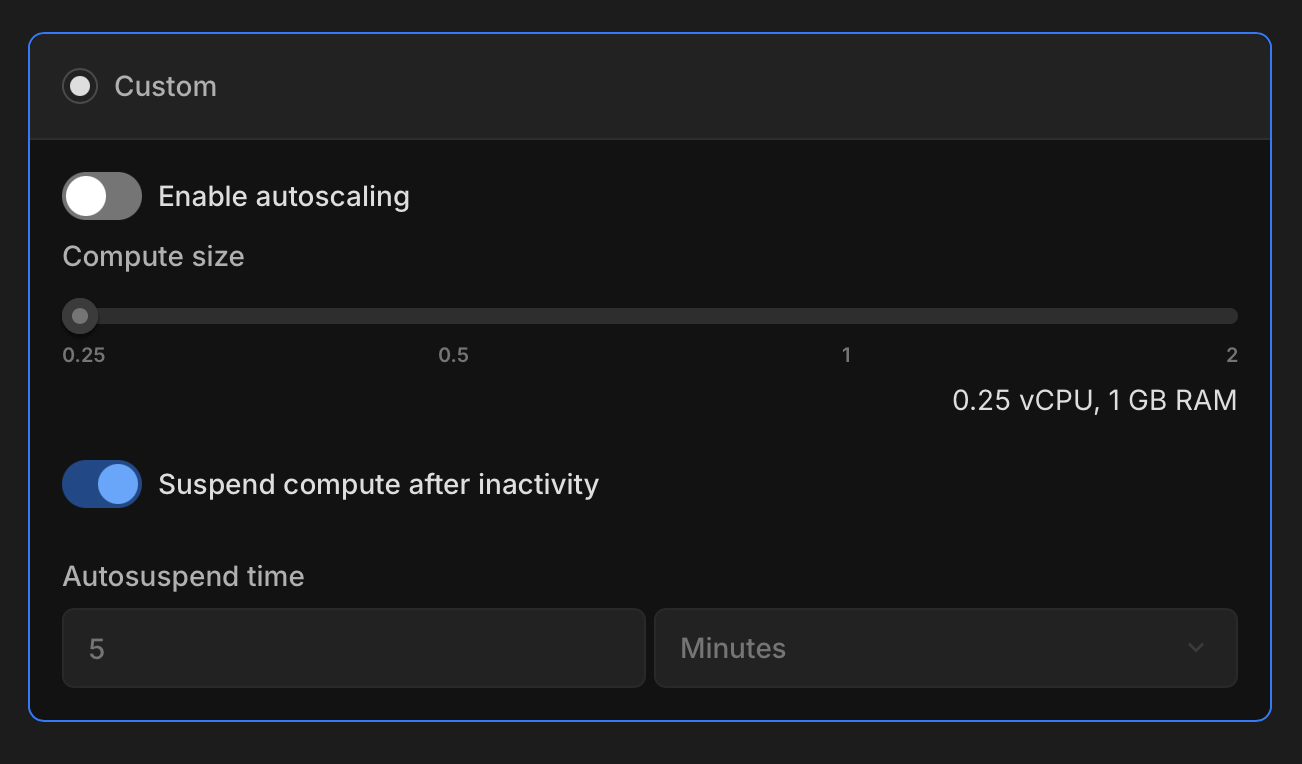
Next, configure your read replica as you would for any other compute. Remember, a read replica in Neon is simply an additional compute endpoint attached to your branch with read-only access to your database.
For example, in the screenshot below, the read replica is configured with a fixed 0.25 CPU and 2 GB RAM capacity, but you can also enable autoscaling with a higher compute max. Make sure to keep autosuspend enabled so your read replicas can scale to zero when not in use.

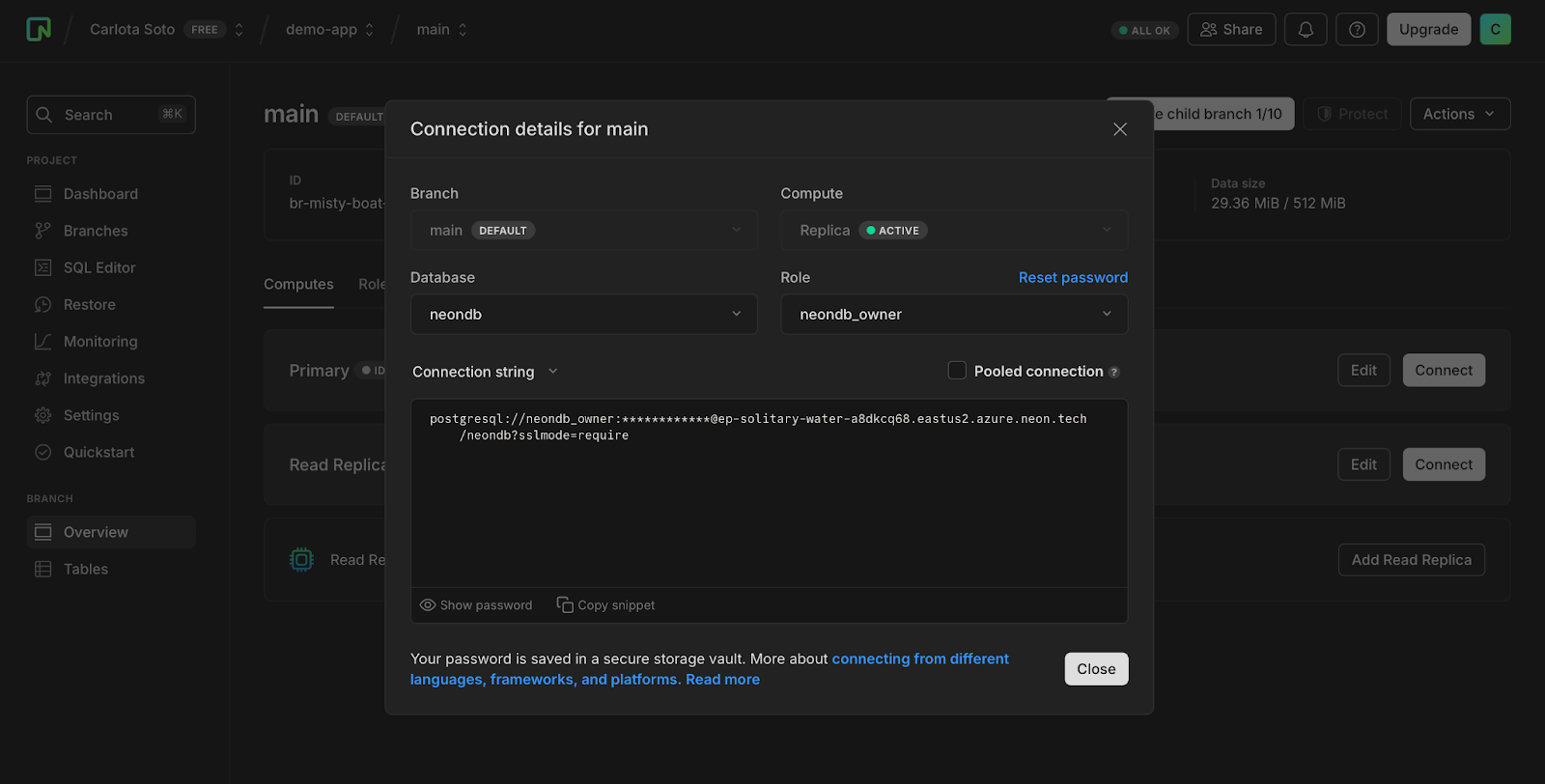
Once you click Create, your read replica will appear in the list of computes attached to your branch. If you want to connect to your branch via the read replica (or allow someone else to), you’ll find a dedicated connection string under Connect:
Go ahead and replicate! If you have any questions, feel free to ask us in Discord.