I got a Slack message from colleagues at a major partner. They’d updated their dev environment to support WebSockets, so that Neon’s serverless driver could be used there, but then they’d run into a weird issue.
The nub of it was this:
This hangs:
const { rows } = await sql`SELECT * FROM pokemon ORDER BY random() LIMIT 10`;This works
const { rows } = await sql`SELECT * FROM pokemon LIMIT 10`;Reproducibly, the query without an ORDER BY ran fine every time. Reproducibly, the query with ORDER BY random() failed every time. Usually, it hung. Occasionally, it came back with an immediate Error: Connection terminated unexpectedly. Either way: it never worked.
I was intrigued by this. I was also keen to fix it.
Our serverless driver redirects the Postgres binary protocol — which is ordinarily carried over TCP — over a WebSocket connection, so that it can be used from serverless platforms that support WebSockets but not TCP.
Our partner was using undici to support WebSockets in Node 18 and above, and ws to support them in Node 17 and below. Node 17 and below worked, Node 18 and above didn’t. Plus, undici’s WebSockets support was labelled as ‘experimental’. So they’d identified undici as a good place to start looking for the problem.
I created a minimal test case to run in Node, and saved it as wstest.mjs:
// uncomment one of these lines to use either ws or undici:
// import WebSocket from 'ws';
import { WebSocket } from 'undici';
// uncomment one of these lines to run either a short or long query:
// const query = 'SELECT * FROM pokemon LIMIT 10';
const query = 'SELECT * FROM pokemon ORDER BY random() LIMIT 10';
import { neonConfig, Pool } from '@neondatabase/serverless';
neonConfig.webSocketConstructor = WebSocket;
const connectionString =
'postgres://jawj:passwd@proj-name.eu-central-1.aws.neon.tech/main';
const pool = new Pool({ connectionString });
const result = await pool.query(query);
console.log(result);
pool.end();Of the four possible combinations of uncommenting here — (ws, undici) x (short query, long query) — the long query sent via undici was the only one that kept failing.
Wiresharking
To try to see where things were getting stuck, I opened Wireshark, entered a capture filter (host proj-name.eu-central-1.aws.neon.tech), ran my test script, and began eyeballing network packets.
But — oh. Our driver’s WebSockets are secure, over `wss:`, so all I saw was the start of a TLS 1.3 negotiation and then lots of encrypted TLS ‘application data’ packets.
What I needed was to supply Wireshark with the TLS keys. Happily, it turns out that Node makes this very straightforward. A brief web search later, I ran:
node --tls-keylog=keylog.txt wstest.mjsI then pointed Wireshark at keylog.txt (via Preferences … > Protocols > TLS > (Pre-)Master-Secret log filename), restarted the capture, and ran the script again.
(1)
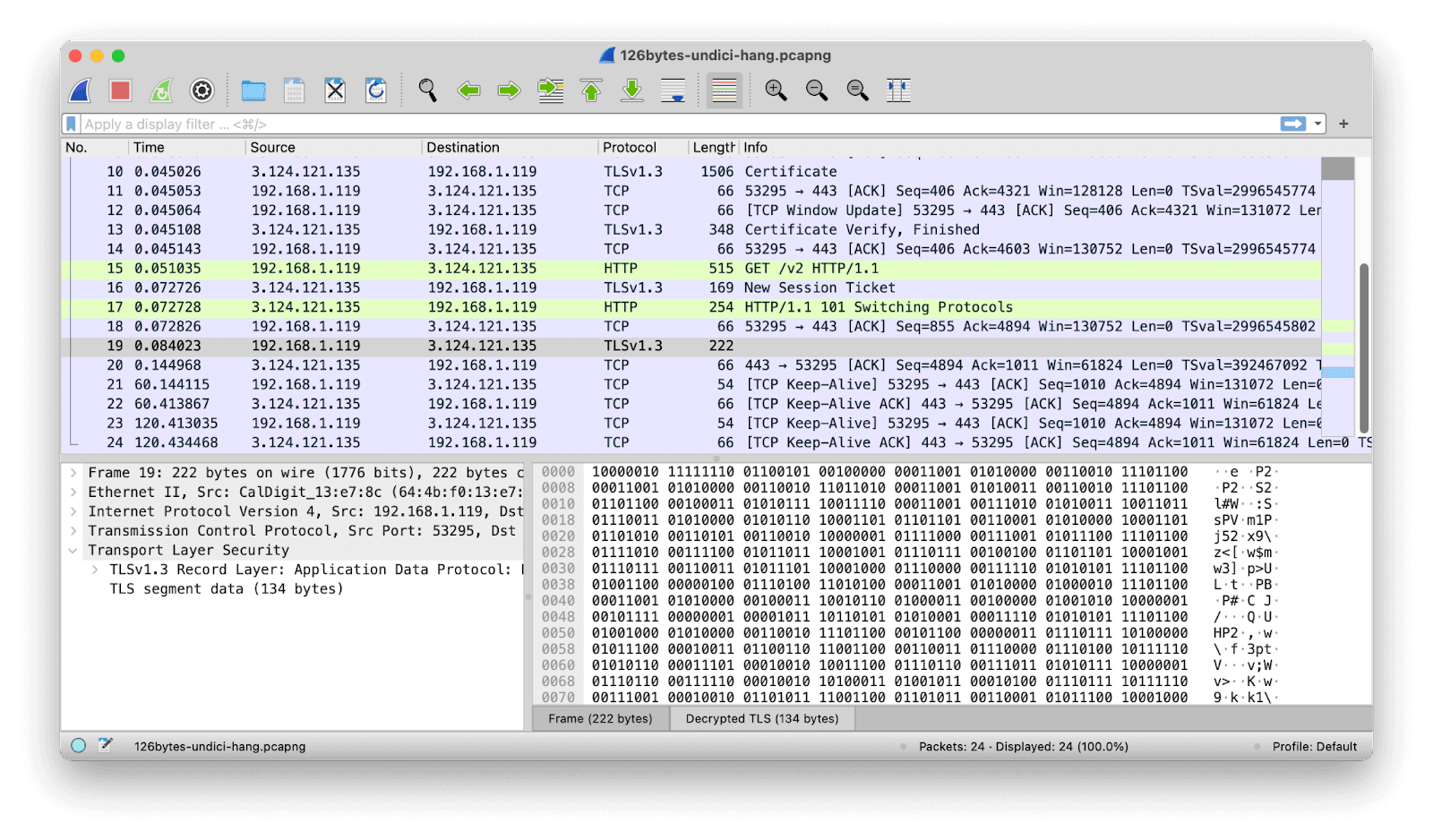
Progress: now we can see the decrypted data. Highlighted in green we have a GET request followed by a HTTP/1.1 101 Switching Protocols message, indicating that the WebSocket connection got accepted by the server. But following that, Wireshark doesn’t identify any WebSocket traffic. Just a single substantive message is recorded, and Wireshark sees it only as a decrypted (but still opaque) TLS transmission.
Note: a database password is shown in, or recoverable from, several screenshots on this page. This password has since been changed!
How does this compare with what we get when we use the ws WebSocket package instead?
(2)
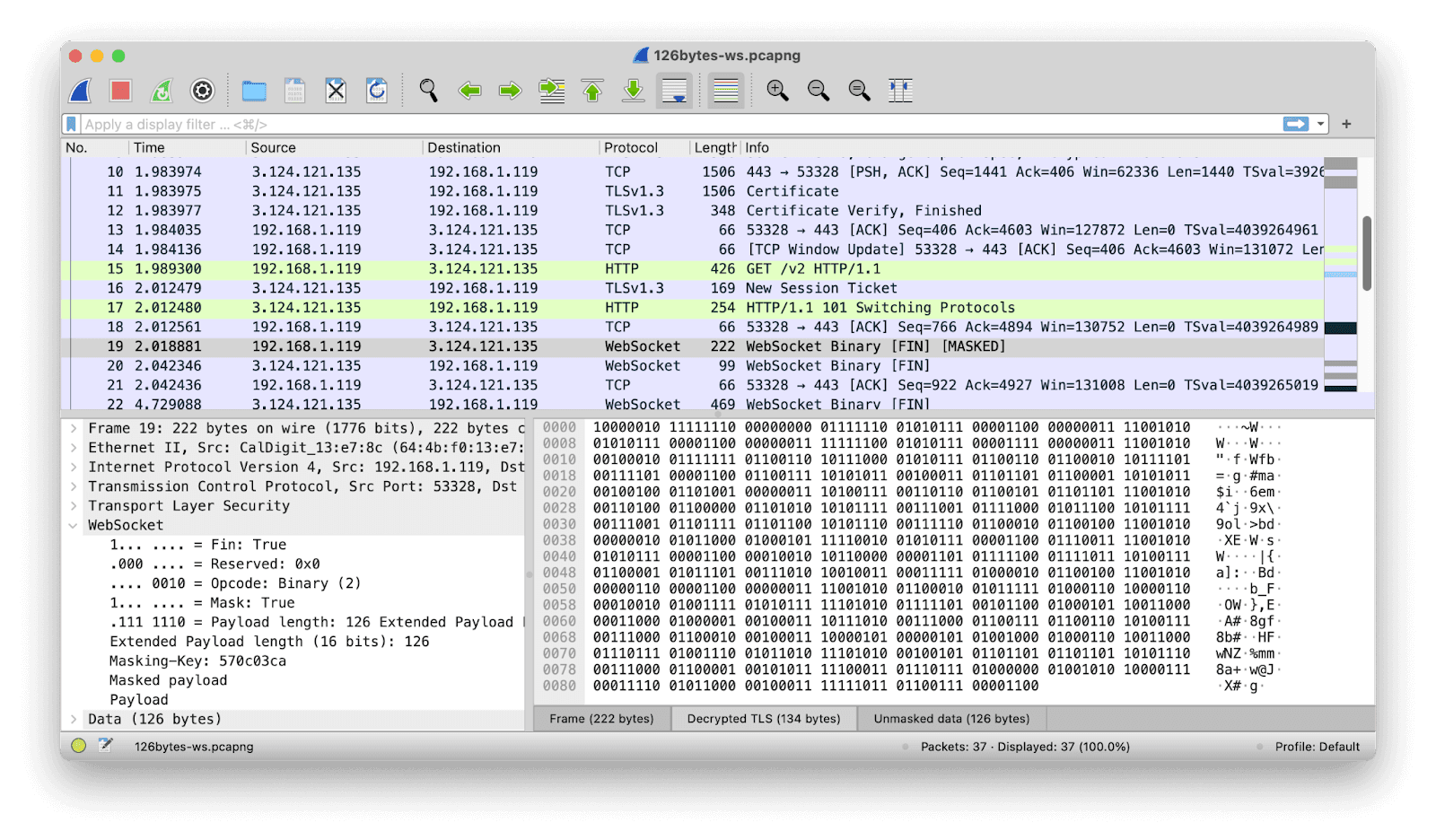
The next substantive packet after the Switching Protocols message has the same 222-byte length as before. But this time it’s identified as a WebSocket Binary message (we can also see that it’s masked, and that it constitutes the final — and indeed only — installment of the data being sent in this particular transmission).
Let’s unmask the data by using the relevant tab at the bottom of the bottom-right-hand pane, and see what’s being sent.
(3)
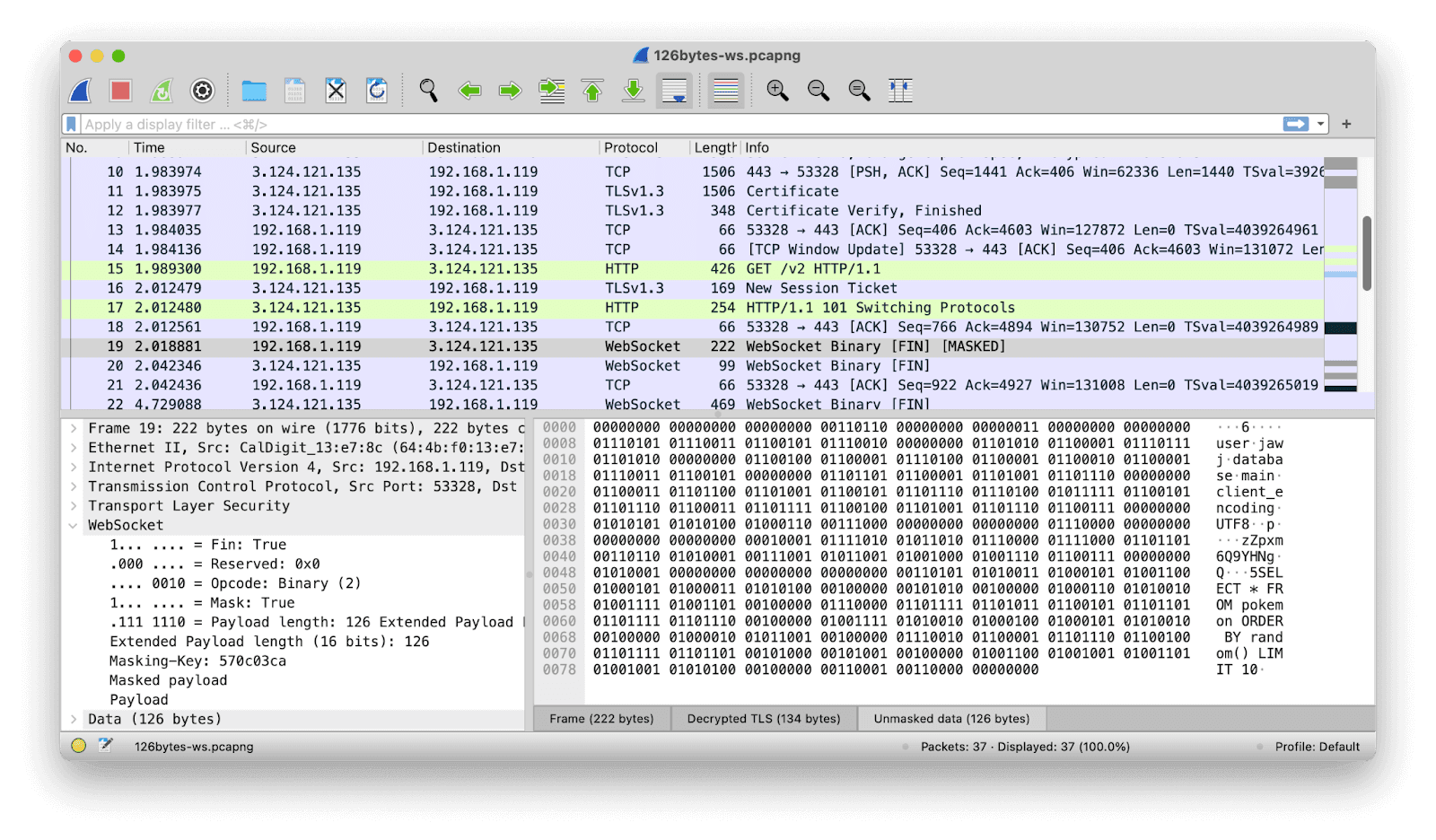
There are three separate short binary Postgres-protocol messages jammed together here: a StartupMessage, a PasswordMessage, and Query message (we pipeline these for speed, as I’ve mentioned before). This is all fine and just as expected.
So: what’s the difference between screenshots 1 and 2, which are the undici and ws versions of the same communication? Byte 1 is the same in both: it says that this is the final (only) packet of this binary transmission. Byte 2 is the same in both, too: it says that the transmission is masked, and that we should treat the next two bytes as a 16-bit payload length.
So then bytes 3 and 4 should be that 16-bit payload length — and this is where things fall apart. The ws message says we have 126 bytes (00000000 01111110) of payload. That sounds plausible. The undici message says we have 25,888 bytes (01100101 00100000) of payload … in a 222 byte packet? Yeah: this one is fishy.
I tried some more requests using undici, and the 2-byte payload length field was different every time. It appeared to contain essentially random numbers. Usually, the supposed payload length was longer than the real length of 126 bytes, and then the request hung, waiting on the promised additional data that was never actually going to be sent. Occasionally, the supposed payload length was shorter than the real length, and in those cases I got that Connection terminated unexpectedly error I noted earlier.
WebSocket payload lengths
It was time to read up on the WebSocket framing protocol and, in particular, how payload lengths are communicated. In the name of saving a few bytes here and there, it turns out there are three different ways a WebSocket payload length can be encoded in a WebSocket frame. Lengths up to 125 bytes are expressed in the last 7 bits (after the mask bit) of the second byte of the frame. For lengths between 126 and 65,535 bytes, those seven bits are set to 126 (1111110), and bytes 3 and 4 hold the length. And for lengths of more than 65,535 bytes, the seven bits are set to 127 (1111111), and the length is then found in the next 8 bytes, 3 through 10.
The RFC illustrates this with the following figure:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
: Payload Data continued ... |
+---------------------------------------------------------------+
A-ha! There’s a clue here about why a shorter query might succeed where a longer query fails. We already saw that the longer query above, SELECT * FROM pokemon ORDER BY random() LIMIT 10, brings the total payload to 126 bytes. As luck would have it, this is exactly the smallest value that requires a 16-bit extended payload length.
By contrast, the shorter query (the one without an ORDER BY clause) will clearly result in a shorter payload length: one that thus fits in the 7 bits of the second byte, and thus exercises a different code path. In fact, we can see that shortening our failing query by just one character — for example, LIMIT 9 in place of LIMIT 10 — would be enough to change the path taken here.
Hacking on undici
With all this in mind, I began to poke around in the undici GitHub repo. It was mercifully straightforward to find the relevant code in lib/websocket/frame.js. I homed in on these few lines:
let payloadLength = bodyLength // 0-125
// ...
if (bodyLength > maxUnsigned16Bit) {
// ...
payloadLength = 127
} else if (bodyLength > 125) {
// ...
payloadLength = 126
}
const buffer = Buffer.allocUnsafe(bodyLength + offset)
// ...
if (payloadLength === 126) {
new DataView(buffer.buffer).setUint16(2, bodyLength)
}These lines are how the 16-bit length value gets written: by creating a throwaway DataView into the buffer that holds the WebSocket frame, and calling its setUint16() method. It’s perhaps a little unexpected that the value isn’t written using the buffer’s own writeUInt16BE() method. But the logic seems basically sound, right? Right?
At this point, I think I made a cup of tea.
I came back to the laptop, recaffeinated, and it hit me! I remembered I’d had a similar am-I-going-mad? run-in with JavaScript’s DataView while working on subtls. Data wasn’t being written where it was supposed to be written, and I’d been at a loss to understand why. After a few minutes tearing my hair out, I’d figured out the fix, and as part of a bigger overall commit I’d added two additional arguments to new DataView():

Buffers, ArrayBuffers and subarrays
How did that fix work? Well, any particular Buffer (or typed array) in Node is backed by an ArrayBuffer. That can either be a dedicated ArrayBuffer, which has the same size as the Buffer itself, or it can be a slice of a larger ArrayBuffer.
A common way to create the latter sort of Buffer — one that’s backed by some part of a larger ArrayBuffer — is to call the subarray() method of an existing buffer. No memory gets copied here. What’s returned by subarray() is a new Buffer object backed by part of the same block of memory that backs the buffer it was called on. This is very useful for optimizing speed and memory use.
Of course, when buffers share the same memory, we have to remember that writing to either one of them could make changes to the other. And, of course, when we do anything with a larger ArrayBuffer that underlies a smaller Buffer — such as passing it to a new DataView, as undici did — we absolutely must make sure we reference the appropriate part of it. (To be honest, it’s a pretty nasty footgun that new DataView() defaults byteOffset to zero and byteLength to the ArrayBuffer’s length, rather than insisting that these arguments are provided explicitly).
Long story short: adding the relevant byteLength and byteOffset to the call to new DataView() immediately fixed undici’s WebSockets issue. I filed a PR and logged off for the day feeling pretty good about it.
Wait, what?
I was awake for an hour or two in the middle of the night, thoughts wandering, when it occurred to me that I didn’t fully understand why this fix had worked here. Sure, it couldn’t do any harm to add in byteLength and byteOffset, but why should they be needed? After all, the buffer whose ArrayBuffer is passed to the DataView was allocated only a few lines before. Nobody appears to have called subarray() here.
Looking at the docs the following morning, I learned something new. Buffer.allocUnsafe() isn’t unsafe only because it omits to zero out the bytes of the buffer it hands over, which was what I’d thought I knew. Buffer.allocUnsafe() also reserves the right to allocate small buffers as sub-arrays of a global pool it keeps lying around for the purpose. (This pool on my installation of Node is set to 8192 bytes, and buffers up to half that size may be allocated from it).
The upshot is that the buffer allocated for a modestly-sized WebSocket frame will very likely have a non-zero byteOffset into its backing ArrayBuffer, because its backing ArrayBuffer is that global pool. Assuming a zero byteOffset for it is therefore Very Bad in two different ways:
- The 16-bit payload length that was supposed to be written as bytes 3 and 4 of the WebSocket frame is not written there. So, instead, what ends up as the alleged payload length, in bytes 3 and 4, is whatever arbitrary data was there already.
- That 16-bit payload length is actually written somewhere else, as bytes 3 and 4 of
Buffer.allocUnsafe()’s global pool. These bytes may well be part of another active buffer, and thus we also stand a good chance of corrupting data elsewhere.
A happy ending
I now knew why the fix worked.
The undici team asked me to also add a unit test for the change, which I did. At the same time, I took the opportunity to simplify the code by using writeUInt16BE() as an alternative to a DataView. My pull request was merged, and has now been released in version 5.22.1 of undici.
Performance: a footnote
A follow-up pull request by an undici dev explains that the DataView approach was originally taken for reasons of performance. I was surprised that creating a throw-away object for this single write would be the quickest way to do things, so I did a little benchmarking of some alternatives:
// option 1 (the buggy original)
new DataView(b.buffer).setUint16(2, value)
// option 2 (the initial fix)
new DataView(b.buffer, b.byteOffset, b.byteLength).setUint16(2, value)
// option 3 (my preferred fix)
b.writeUInt16BE(value, 2);
// option 4 (bit-twiddling shenanigans)
b[2] = value >>> 8;
b[3] = value & 0xff;
The bit-twiddling option is the fastest of these, at 90ms for a million iterations on my Intel MacBook. But the writeUInt16BE() approach is only marginally slower at 100ms, easier on the brain, and more than twice as fast as using DataView. To be honest, these differences (over a million iterations) are so small that I’d go for readability every time. In any case, the use of DataView here was an optimization that, though intended to speed things up, actually slowed things down … and broke them utterly in the process.